先日、eGPUを導入したので計算能力の向上幅を大づかみすることにした。
ベンチマークの前に…
計算能力の優劣はコア数や周波数による計算能力だけでなく、メモリ帯域でも決まる。これを簡単にモデル化したものをRooflineモデルと呼ぶ。 データ規模あたりの計算量で計算タスクを抽象化し(横軸)、どの程度の計算能力(縦軸)が期待できるか見積もる際、 あるいは理論上限能力値に対してどの程度性能を発揮しているか評価するときに使う。
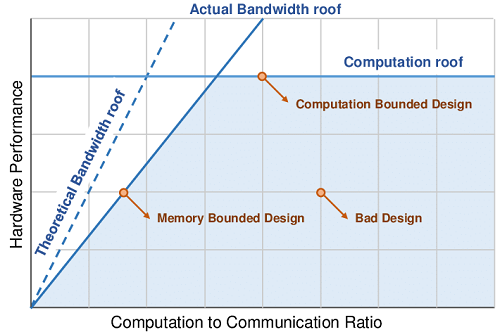
このモデルはデータ量に対して計算量が少ないタスクではメモリ帯域が計算能力の上限を決めることを表現している。モデルを使った、より専門的な分析の事例としてはPerformance Analysis of GPU-Accelerated Applications using the Roofline ModelやPerformance Tuning with the Roofline Model on GPUs and CPUsなどが参考になると思う。 これら2つは、計算機の能力がどこで頭打ちになるかデバイスの仕組みとともに解説もされている。
細かい内訳を見ればIn-Datacenter Performance Analysis of a Tensor Processing Unitで示されるようにデバイスごとにRooflineが異なり、 同じタスクでもメモリで性能が制約されたり、コアの性能を出し切ったりということもあるかと思う。

しかし、Adrián Castelló et al., 2019によれば、Deep Learningの有名なネットワークは十分に「コア性能」が使い切れるように設計されているようである。

そこで大胆な割り切りをして単純にDeep Learningモデルのトレーニング、推論にかかる単位時間を使って比較を行うことにする
(結局、余所と同じです)
機材
- Dell Inspiron 7490 (2019)
- Intel Core i7-10510U
- RAM 16GB, LPDDR3, 2133MHz
- 組込GPU: NVIDIA GeForce MX250
- eGPU: NVIDIA GeForce RTX3060 (12GB)
- Driver 516.94
- Thunderbolt 3
- Windows 11 (22622.450 ni_release)
- Python 3.10 (Anaconda)
- CUDA 11.3
- Pytorch 1.12.1
ベンチマーク
こちらを使います
改めて環境の確認。両方GPUを生かしておくとクラッシュするので片方ずつ有効化する。
$ nvidia-smi --query-gpu=name,driver_version --format=csv,noheader
NVIDIA GeForce RTX 3060, 516.94
$ python
Python 3.10.4 | packaged by conda-forge | (main, Mar 30 2022, 08:38:02) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.__version__
'1.12.1'
>>> torch.version.cuda
'11.3'
GPUを切り替えると下記だけ異なる
$ nvidia-smi --query-gpu=name,driver_version --format=csv,noheader
NVIDIA GeForce MX250, 516.94
結果
比較のため元レポのデータも抜粋した。MX250はメモリ不足でFP32の条件では動作せず、FP16も計測時間が長いのでVGG16のみ。
今回導入した3060は1080Tiにわずかに劣る性能で、Google ColabratoryのTesla T4より快適という位置づけになりそう。GPUの専有時間が心配になりませんし、NeRFなど手元で3Dをグリグリしたい用途で優位性を発揮してもらいましょう。
| Device | 出典 | 環境 | vgg16 | resnet152 | densenet161 | |||
|---|---|---|---|---|---|---|---|---|
| eval(ms) | train(ms) | eval(ms) | train(ms) | eval(ms) | train(ms) | |||
| Titan V | github | PyTorch 0.3
CUDA 9
FP32
|
31.3 | 108.8 | 48.9 | 180.2 | 52.4 | 174.1 |
| 1080 Ti | 同上 | 39.3 | 131.9 | 57.8 | 206.4 | 62.9 | 211.9 | |
| V100 | 同上 | 26.2 | 83.5 | 38.7 | 136.5 | 48.3 | 142.5 | |
| 2080 Ti | 同上 | 30.5 | 102.9 | 41.9 | 157.0 | 47.3 | 160.0 | |
| Tesla T4 | 今回計測
Colaboratory
|
PyTorch 1.12
CUDA 11.3
FP32
|
72.4 | 223.6 | 109.1 | 375.9 | 108.3 | 367.2 |
| 3060 | 今回計測 | PyTorch 1.12
CUDA 11.3
FP32
|
45.6 | 146.9 | 69.4 | 273.6 | 78.6 | 293.8 |
| 3060 | 今回計測 | PyTorch 1.12
CUDA 11.3
FP16
|
33.4 | 112.0 | 52.4 | 244.6 | 60.7 | 295.7 |
| MX250 | 今回計測 | PyTorch 1.12
CUDA 11.3
FP16
|
3,147.2 | 10,344.4 | - | - | - | - |
考察
ある特定のタスクの結果をもって全体的な性能を示すことは難しい。しかし、個人では資金がアクセスできるデバイスの数に制限をかけることから平等条件でない指標を複数見比べながら購買計画をたてざるえないと思う。
そこで試験的にベンチ結果を推測する手立てを考えた。
理論計算能力との相関
測定した処理時間の逆数がFLOPSの次元なので逆数を取ってプロットし、GPU性能との相関を取った。GPUの性能はGPU DatabaseのFP32の性能(TFLOPS)を使った。
3060はデータバス帯域が狭いため異常値になる予感もあったが、概ねTFLOPSに比例した結果が観察され、VGG16に関しては(標本サイズからあまり意味のない数値かも知れないが) 切片=0の回帰に対して何れも$ R^2_7 = 0.984 $ である。
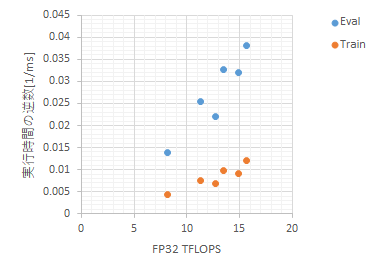
Deep Learningの著名モデルを扱う前提であればFP32を指標にGPUの買い替えや買い増しを検討することはあながち間違いではなさそうである。
3Dベンチマークとの相関
理論計算能力値で心配な場合は3Dゲームのベンチマーク結果が実践値という意味で利用可能かもしれない。データソースとしても潤沢でGeForceならばまず数値が見つけられるはず。
結論だけ報告すると、こちらもベンチマークスコアと概ね相関を取れたが、Tesla系列のデータがあるわけもなくGoogle Colaboratoryとの比較などといった実用面の観点から企画倒れであった。
参考
- GPU Database | TechPowerUp
- 決定係数 R2の違い: Excel, OpenOffice, LibreOffice および統計解析ソフト R を用いて
- GPU(グラフィックボード)性能比較~3Dベンチマークについて | パソコン工房
- Deep Learning GPU Benchmarks - V100 vs 2080 Ti vs 1080 Ti vs Titan V
No comments:
Post a Comment